Research
Jump to:
- Google Scholar Page
- Alignment of Machine Explanations and Human Interpretatiosn
- Parsimonious Representation Learning
- Accessible and Implementable Biomedical Applications
Alignment of Machine Explanations and Human Interpretations
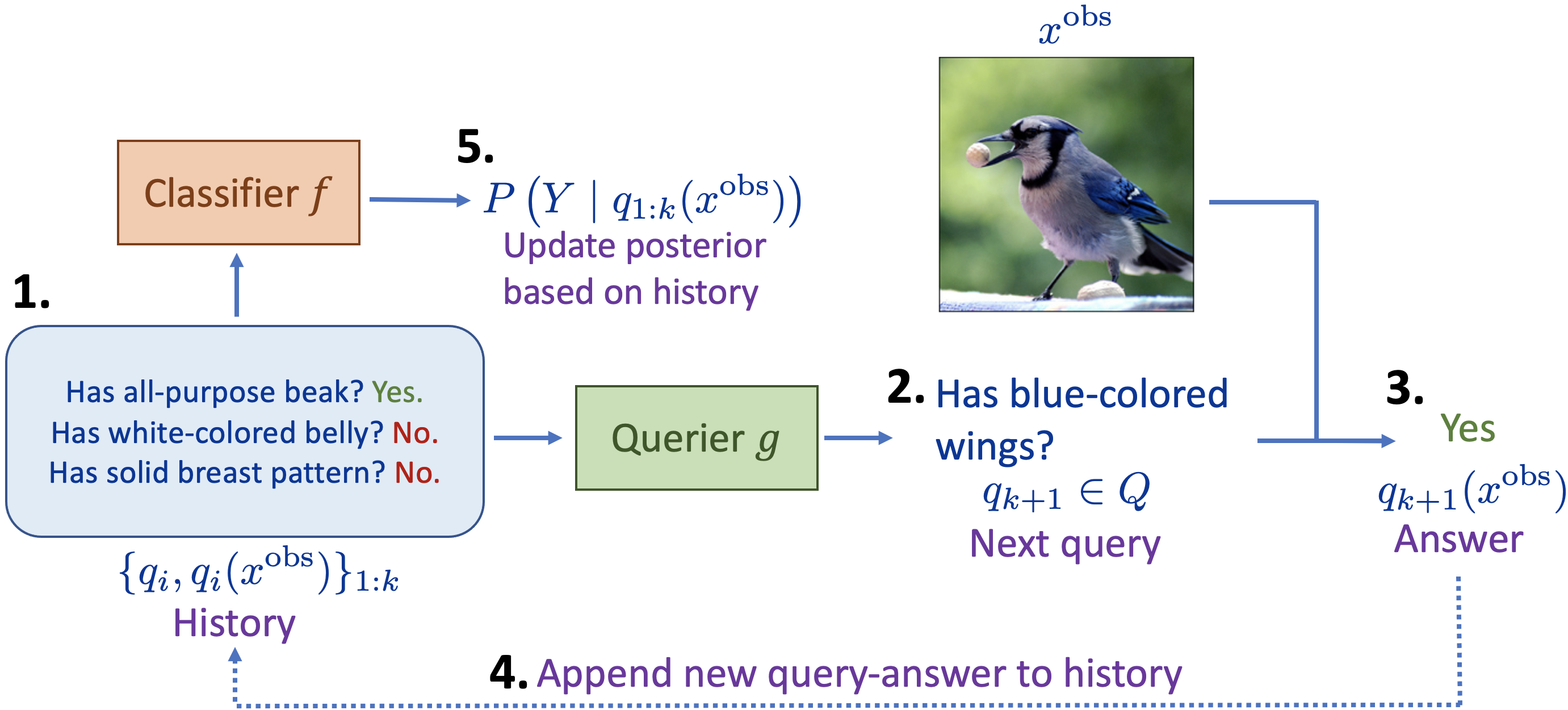
The fundamental purpose all machine learning models share is that they are built for humans: we define a task, provide a data, and hope to uncover mysterious factors that drive prediction and utilize it to advance other purposes. One major barrier to actualize the potential of such models are how little we understand why they work. We approach this problem by building interpretable models: model’s explanations should not only be semantically meaningful, but grounded in reality and how humans understand. Just like how a doctor perform diagnoses on patients, how do we incorporate multi-modality? Question-answering? Grounded in evidence? We aim to bridge this gap with translational research across domain knowledge, statistics, linguistics, and philosophy.
- Aditya Chattopadhyay*, Kwan Ho Ryan Chan*, René Vidal. Bootstrapping Variational Information Pursuit with Foundation Models for Interpretable Image Classification. The Twelve International Conference on Learning Representations, 2024.
- Aditya Chattopadhyay, Kwan Ho Ryan Chan, Benjamin D. Haeffele, Donald Geman, René Vidal. Variational Information Pursuit for Interpretable Predictions. The Eleventh International Conference on Learning Representations, 2023.
- Jinqi Luo, Kwan Ho Ryan Chan, Dimitris Dimos, René Vidal. Contextual Knowledge Pursuit for Faithful Visual Synthesis. Preprint, 2024.
- Stefan Kolek, Aditya Chattopadhyay, Kwan Ho Ryan Chan, Hector Andrade-Loarca, Gitta Kutyniok, Réne Vidal. Learning Interpretable Queries for Explainable Image Classification with Information Pursuit. Preprint. 2024.
Parsimonious Representation Learning
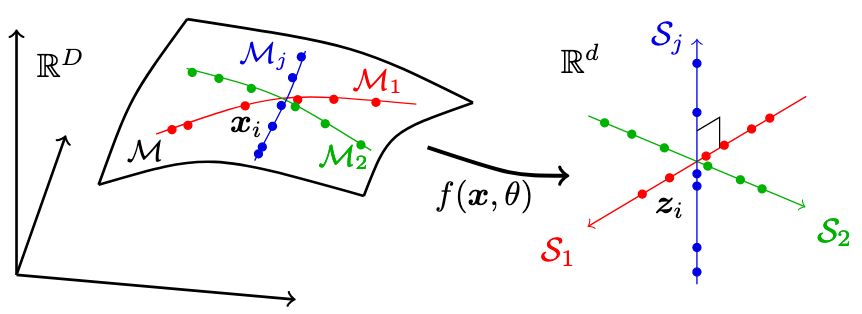
Classical machine learning makes observable and well-posed assumptions about the data distribution, laying sufficient ground work for transparent understanding of theoretical properties and practical performance for the task at hand. On the extreme, modern deep learning makes little-to-none assumptions about the data, but find success by overpowering the model with insurmountable amount of data, making it challenging to have any guidance on basic properties and choices of architecture and optimization method. The goal of learning parsimonious representations is to bridge the old and the new, by finding reasonable and structured assumptions about the data and the task, hence allowing research opportunities for achieving both holistic theoretical understanding and strong practical performance.
- Kwan Ho Ryan Chan*, Yaodong Yu*, Chong You*, Haozhi Qi, John Wright, Yi Ma. ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction. Journal of Machine Learning Research, 2021.
- Yaodong Yu*, Kwan Ho Ryan Chan*, Chong You, Chaobing Song, and Yi Ma. Learning Diverse and Discriminative Representations via the Principle of Maximal Coding Rate Reduction. Neural Information Processing Systems, 2020.
- Tianjiao Ding, Shengbang Tong, Kwan Ho Ryan Chan, Xili Dai, Yi Ma, Benjamin D. Haeffele. Unsupervised Manifold Linearizing and Clustering. International Conference on Computer Vision, 2023.
- Xili Dai, Shengbang Tong, Mingyang Li, Ziyang Wu, Kwan Ho Ryan Chan, Pengyuan Zhai, Yaodong Yu, Michael Psenka, Xiaojun Yuan, Heung Yeung Shum, Yi Ma. Closed-Loop Data Transcription to an LDR via Minimaxing Rate Reduction. Entropy, 2022.
- Christina Baek, Ziyang Wu, Kwan Ho Ryan Chan, Tianjiao Ding, Yi Ma, Benjamin D. Haeffele. Efficient Maximal Coding Rate Reduction by Variational Forms. Conference on Computer Vision and Pattern Recognition, 2022.
Accessible and Implementable Biomedical Applications

Deep Learning Biomedical applications are challenging to implement because data and model assumptions are often too idealized and unrealistic, leaving room for error and making them less practical. Real-life considerations such as financial cost, population bias, measurement errors, missing values are often ignored, or even worse, substituted with false but seemingly true assumptions. To make biomedical machine learning truly implementable, we must work with clinicians and carefully determine the appropriate design for our problem. Only then, we have any hope for meaningful applications and trustworthy usage of deep learning models in clinical settings. Our goal is exactly as such.
- Sam Nguyen*, Kwan Ho Ryan Chan*, Braden Soper, Jose Cadena, Paul Kiszka, Lucas Womack, Mark Work, Joan M. Muggan, Steven T. Haller, Jennifer Hanrahan, David J. Kennedy, Deepa Mukundan, Priyadip Ray. Budget Constrained Machine Learning for Early Prediction of Adverse Outcomes for COVID-19 Patients. Scientific Reports by Nature, 2021.
- Braden C Soper, Jose Cadena, Sam Nguyen, Kwan Ho Ryan Chan, Paul Kiszka, Lucas Womack, Mark Work, Joan M Duggan, Steven T Haller, Jennifer A Hanrahan, David J Kennedy, Deepa Mukundan, Priyadip Ray. Dynamic modeling of hospitalized COVID-19 patients reveals disease state–dependent risk factors. Journal of the American Medical Informatics Association, 2022
- Daniel H. Kwon, Jose Cadena, Sam Nguyen, Kwan Ho Ryan Chan, Braden Soper, Amy L. Gryshuk, Julian C. Hong, Priyadip Ray, Franklin W. Huang. COVID‐19 outcomes in patients with cancer: Findings from the University of California health system database. Cancer Medicine, 2022.
*authors contributed equally.